IP im Webauftritt blockieren
Heute Abend hat mein Appmonitor [1] festgestellt, dass meine Webseite keine Antworten mehr beim Monitoring-Check sendet.
Nach einigen Minuten kam der Webservice wieder … und verabschiedete sich aufs Neue.
In der Webseitenstatistik Matomo [2] war schnell ein potentieller Kandidat gesichtet, der “etwas” mehr als üblich Seiten vom Webauftritt abruft: 4000 Requests über 5 Stunden - das ist mehr als das übliche Mass von 1 bis 2-stelligen Seitenaufrufen von einem Benutzer.
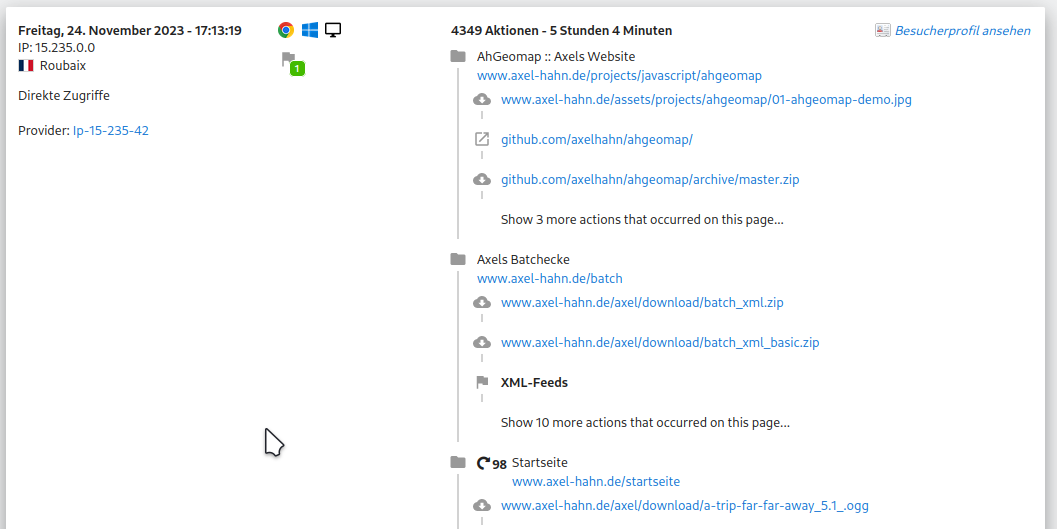
Abhilfe:
Mein Provider nutzt den Apache Httpd. In der .htaccess im Webroot habe ich die gefundene IP blockiert. Matomo anonymisiert die IP-Adressen - ich sehe sie nicht komplett. Ich war so frei und habe den kompletten D Block ausgeknipst.
... # -- DENY given IP addresses -- <RequireAll> Require all granted # 2023-11-24 Roubaix FRA - provider ip-15-235-42.net Require not ip 15.235.42.0/24 </RequireAll> ...
Weiterführende Links
- IML Appmonitor Docs (Freie Software; PHP) Source
- matomo.org - Webseiten-Analyse (Freie Software; PHP und Mysql)
Dokus für 2 Bash-Projekte
Ich skripte meine Dinge hauptsächlich in Bash.
Und weil niemand etwas nutzt, was nicht dokumentiert ist, habe ich 2 neue Dokumentationen online gestellt:
(1)
Kürzlich habe ich eine Bash-Komponente geschrieben, die die Handhabe der ANSI Farben vereinfacht.
Man kann eingfach Farben für Vordergrund und Hintergrund setzen - mit Namen einer Farbe oder HTML-CSS-Farbangabe.
Doc zu bash_colorfunctions
Rein zur Veranschaulichung: damit kann man farbige Texte ausgeben mit
color.echo "white" "green" "Yep, it seems to work!"
… oder aber die Farbe nur setzen, um nachfolgende Kommandos in jener Farbe die Ausgabe machen zu lassen. Zum Aufheben der Farbdefinition ruft man ein color.reset auf:
color.fg "blue" ls -l color.reset
(2)
Schon einige Monate auf Github ist mein Projekt, das mit Hilfe eines lokal installiertten Nginx den Zugriff auf eine Webapplikation als Docker Container mit Https und mit Namen der Applikation ansprechen lässt.
Doc zu nginx-docker-proxy
Beide Projekte sind freie Software und Opensource.
Bash: lsup zur Anzeige der Dateiberechtigungen
Wie oft ich das schon im Linux Filesystem gebraucht habe: in einem aktuellen oder angegebenen Verzeichnis prüfen, ob der Linux-Benutzer XY bis dorthin “durchkommt” und Berechtigungen in einem Verzeichnis oder auf eine Datei hat.
Also schrieb ich ein Shellskript. Man ruft es mit einem Parameter für ein zu prüfendes Verzeichnisses auf. Oder ohne Parameter für das aktuelle Verzeichnis.
Ich fange mal mit dessen Ausgabe an:
$ lsup drwxr-xr-x 1 root root 244 Apr 2 23:34 / drwxr-xr-x 1 root root 100 Jun 4 2022 /home drwx------ 1 axel autologin 1.7K May 25 18:17 /home/axel drwxr-xr-x 1 axel autologin 232 May 25 19:50 /home/axel/tmp
Ab dem Root-Verzeichnis werden mit ls -ld alle Verzeichnisebenen bis zum angegebenen Punkt angezeigt.
Syntax:
$ lsup -h ===== LSUP v1.3 :: make an ls upwards ... ===== Show directory permissions above by walking from / to the given file. You can add no or one or multiple files as params. SYNTAX: lsup Walk up from current directory lsup FILE [FILE N] Walk up from given file/ directory If the target is relative it will walk up to the current directory lsup -h Show this help and exit EXAMPLES: lsup lsup . lsup /var/log/ lsup my/relative/file.txt lsup /home /tmp /var
Zur Installation: als User root;: cd /usr/bin/ und nachfolgenden Code in eine Datei namens “lsup” werfen und ein chmod 0755 lsup hinterher.
#!/usr/bin/env bash
# ======================================================================
#
# Make an ls -d from root (/) to given dir to see directory
# permissions above
#
# ----------------------------------------------------------------------
# 2020-12-01 v1.0 Axel Hahn
# 2023-02-06 v1.1 Axel Hahn handle dirs with spaces
# 2023-02-10 v1.2 Axel Hahn handle unlimited spaces
# 2023-03-25 v1.3 Axel Hahn fix relative files; support multiple files
# ======================================================================
_version=1.3
# ----------------------------------------------------------------------
# FUNCTIONS
# ----------------------------------------------------------------------
function help(){
local self=$( basename $0 )
cat <<EOH
===== LSUP v$_version :: make an ls upwards ... =====
Show directory permissions above by walking from / to the given file.
You can add no or one or multiple files as params.
SYNTAX:
$self Walk up from current directory
$self FILE [FILE N] Walk up from given file/ directory
If the target is relative it will walk up
to the current directory
$self -h Show this help and exit
EXAMPLES:
$self
$self .
$self /var/log/
$self my/relative/file.txt
$self /home /tmp /var
EOH
}
# ----------------------------------------------------------------------
# MAIN
# ----------------------------------------------------------------------
if [ "$1" = "-h" ]; then
help
exit 0
fi
test -z "$1" && "$0" "$( pwd )"
# loop over all given params
while [ $# -gt 0 ]; do
# param 1 with trailing slash
mydir="${1%/}"
if ! echo "$mydir" | grep "^/" >/dev/null; then
mydir="$( pwd )/$mydir"
fi
ls -ld "$mydir" >/dev/null 2>&1 || echo "ERROR: File or directory does not exist: $mydir"
ls -ld "$mydir" >/dev/null 2>/dev/null || exit 1
mypath=
arraylist=()
arraylist+=('/')
IFS="/" read -ra aFields <<< "$mydir"
typeset -i iDepth=${#aFields[@]}-1
for iCounter in $( seq 1 ${iDepth})
do
mypath+="/${aFields[$iCounter]}"
arraylist+=( "${mypath}" )
done
# echo ">>>>> $mypath"
eval "ls -lhd ${arraylist[*]}"
shift 1
test $# -gt 0 && echo
done
# ----------------------------------------------------------------------
Viel Spass damit!
Fontawesome Upgrade von Version 5 auf Version 6
Um Fontawesome von Version 5 auf 6 zu aktualisieren, gibt es einen Upgrade-Guide [1].
Aber das ist viel zu kompliziert :-)
nachdem ich einige Web-projekte umgestellt habe (das Intranet unseres Instituts, IML Appmonitor, ahCrawler, Pimped Apache Status) kann ich meinen Ansatz präsentieren:
- Man entferne das eingebundene CSS File von Fontawesome 5 und ersetze es durch das der Version 6, z.B.:
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.4.0/css/all.min.css" integrity="sha512-iecdLmaskl7CVkqkXNQ/ZH/XLlvWZOJyj7Yy7tcenmpD1ypASozpmT/E0iPtmFIB46ZmdtAc9eNBvH0H/ZpiBw==" crossorigin="anonymous" referrerpolicy="no-referrer" />
- Die meisten Icons sollten nach wie vor da sein. Aber wir aktualisieren einmal die Schreibweise der CSS Klassen für die Version 6.
- im Projektordner Suchen und Ersetzen “fas fa” –> “fa-solid fa”
- im Projektordner Suchen und Ersetzen “far fa” –> “fa-regular fa”
Damit sind 98% erledigt. Nun sollte man die Webseite nochmal genau anschauen. Es kann sein, dass es noch das ein oder andere Prefix umzustellen gilt (z.B. für Brands). Oder aber es gibt auch einige (wenige) Icons, die nun anders heissen - wenngleich sich diese vielleicht nur schwer finden lassen - für diese muss man in [2] die neue Schreibweise ermitteln.
Viel Glück bei der Umstellung!
Weiterführende Links:
Pimped Apache Status - PHP 8.2 kompatibel
Der Pimped Apachestatus ist ein Webtool, dass die etwas schwer verdauliche Apache Serverstatus Page aufbereitet. Es gibt verschiedene Ansichten, sortier- und filterbare Tabellen und Graphen. Das ganze funktioniert nicht nur für einen einzelnen Server, sondern auch für mehrere Webhosts, z.B loadbalante Webeiten.
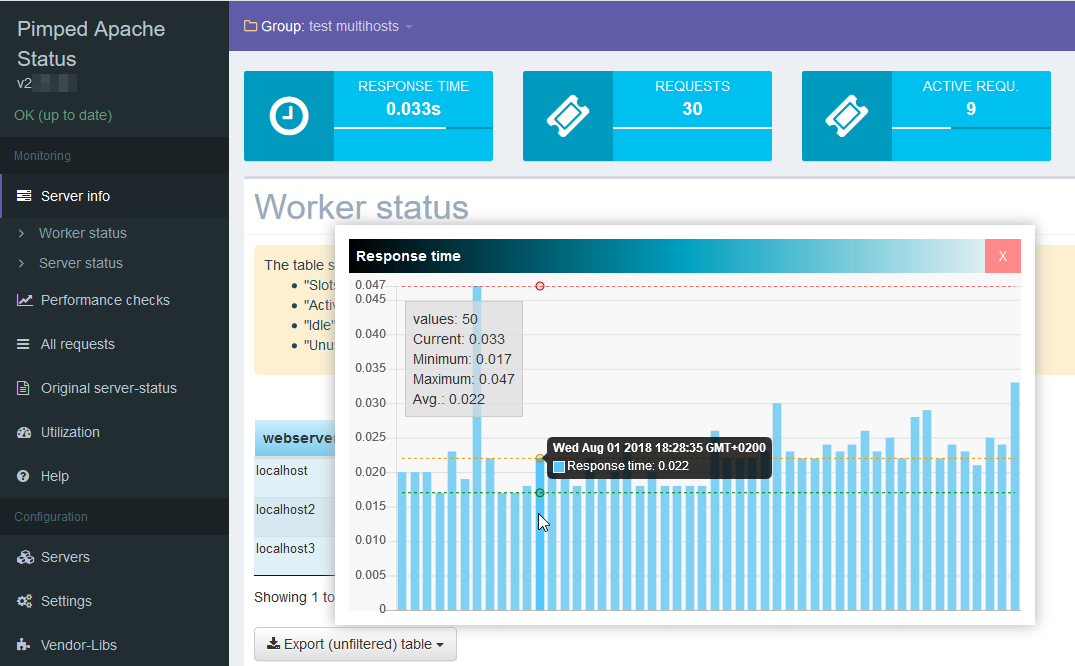
Am Wochenende gab es ein Update, in dem einige Vendor-Bibliotheken aktualisiert wurden.
Da die als kompatibel bestätigte Version 8.0 alsbald ausläuft, wurde es mit neueren PHP Versionen getestet. Es ist nunmehr PHP 8.2 kompatibel.
Zum Aktualisieren meldet sich der Updater. Bei Installationen mit git bitte git pull verwenden.
Weiterführende Links:
Timeshift und Prozentrechnung
Timeshift speichert Snapshots eines Linux-Systems. Es kann sich u.a. als Hook in den Paketmanager einklinken und vor jedem Update einen Snapshot anlegen, um im Falle eines Nicht-Funktionierens zurückzurollen.
- Wenn die Snapshots auch auf der Systemdisk abgelegt werden, wird das Grub-Menü um die Auswahl der letzten Snapshots erweitert.
- Falls nicht, wird ein Rsync zum Sichern des Snapshots bemüht. Wenn man sein Linux booten kann (also notfalls von USB Stick), kann man Timeshift auch so einen anderen Stand wiederherstellen lassen.
Einen kleinen Schönheitsfehler gibt es aber. Im CLI Modus gibt Timeshift eine Fortschrittsinfo aus. Dumm nur, wenn es bei 100% gar nicht fertig ist.
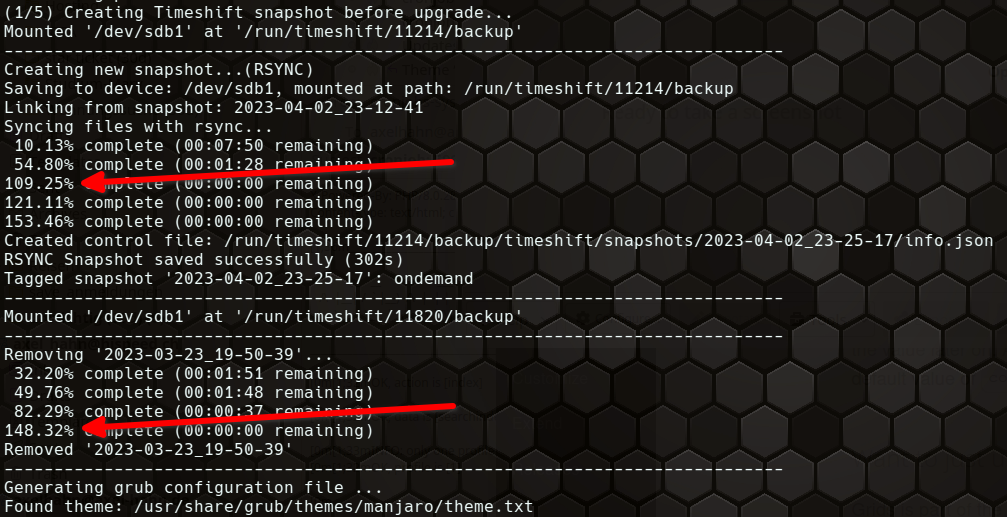
Naja, ich kann darüber hinwegsehen. Wenn der Moment kommt, wo man mal ein Backup braucht, ist man froh um jeden verfügbaren Zwischenstand von so vielen Informationen wie möglich.
Ich fahre auf meinen Linux-PCs mit einer Kombination von Timeshift und Restic (IML Backup). Aber man will ja selbst keinen interaktiven Aufwand und sich nicht darum kümmern. Aber ich weiss, dass ich mich auf das Funktionieren beider Varianten in deren Kombination mit Snapshots und Datei-Backups verlassen kann.
Weiterführende Links
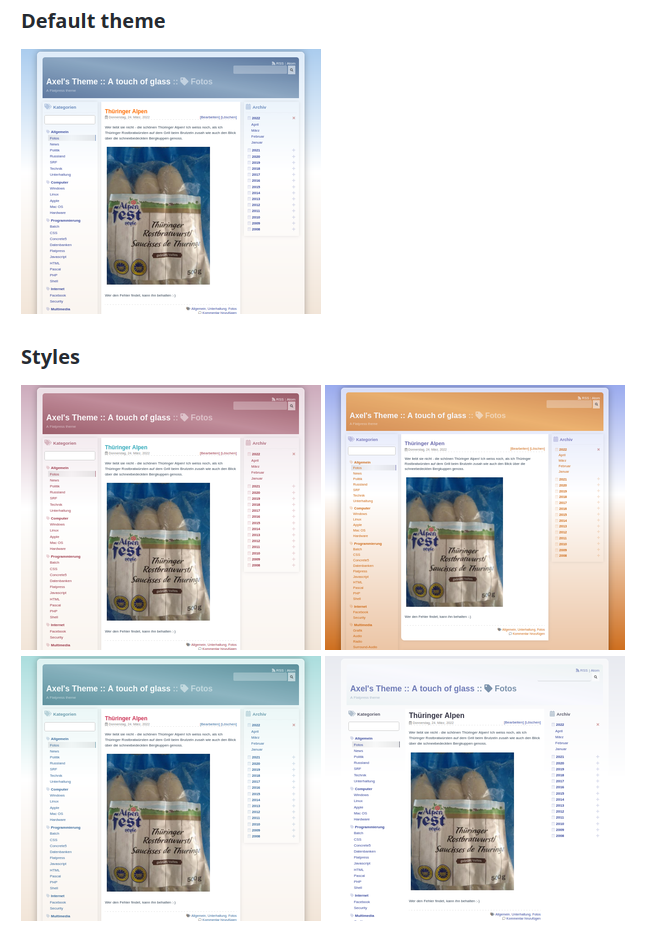
Theme “A touch of glass” aktualisiert
Ich habe einmal für den Blog Flatpress ein Theme bereitgestellt.
Die schlechte Nachricht: Nach Update auf die aktuelle Flatpress-Version ging leider nicht mehr viel.
Die gute: es war einfach zu beheben.
Weiterführende Links
Ansible git: detected dubious ownership in repository
Wir lassen diverse Applikationen mit Ansible von einem Git-Repository installieren. Etwa so:
- name: 'install - Clone repo {{ repo_url }}'
ansible.builtin.git:
repo: '{{ repo_url }}'
dest: '{{ install_dir }}'
Dummerweise kommt dann noch ein Verschenken der Berechtigungen hinterher.
Seit Kurzem - mit einer neueren Git Version - häufen sich Abbrüche beim Git pull
detected dubious ownership in repository
Und auch die Lösung wird in der Fehlermeldung mitgegeben:
git config --global --add safe.directory [Verzeichnis]
Ja denn … packen wir doch einen Schnipsel hierfür dazu:
# set install dir as safedir ...
- name: "FIX - add installdir {{ install_dir }} as safedir"
ansible.builtin.shell: |
git config --global --get-all safe.directory \
| grep "{{ install_dir }}" \
|| git config --global --add safe.directory "{{ install_dir }}"
Wenn es ein paar mehr Server sind, sollte man sich das in in eine Rolle verpacken, um es etwas abstrakter zu halten.
Zum Reparieren packt man es zur einmaligen Ausführung des Playbooks VOR das ansible.builtin.git … aber dann gehört es dahinter.
Der Shell-Aufruf präft, ob der Pfad bereits aufgenommen ist - nur wenn nicht, wird er hinzugefügt. Ansonsten würde ein mehrfaches “add” zu zigfachen Duplikaten desselben Pfades führen.
Fehlermuster im Streamripper
Ich schrieb vor nicht allzu langer Zeit einen Blogeintrag, um in Streamripper2 die Aufnahme-Funktion besser zu nutzen.
Diese muss man konfigurieren - also schlusendlich einen Kommandozeilenaufruf hinterlegen. Klassischerweise wird für Radiostreams das Tool Streamripper konfiguriert - und um eine optische Ausgabe zu haben, setzte man einen Konsolenaufruf davor. Ich fand das sehr bescheiden - sehr oft war bei egenen Versuchen war das Konsolenfenster gleich wieder zu und damit auch eine etwaige Fehlermeldung weg. Das ist doch nur unbefriedigend.
So fing alles an. Ich kann zum Glück etwas Shellprogrammierung.
Es sollte zunächst ein kleiner Wrapper sein, der anzeigt, welches Kommando mit welchen Parametern aufgerufen wird - und im Falle eines Abbruchs mich auch den Fehlertext lesen lässt.
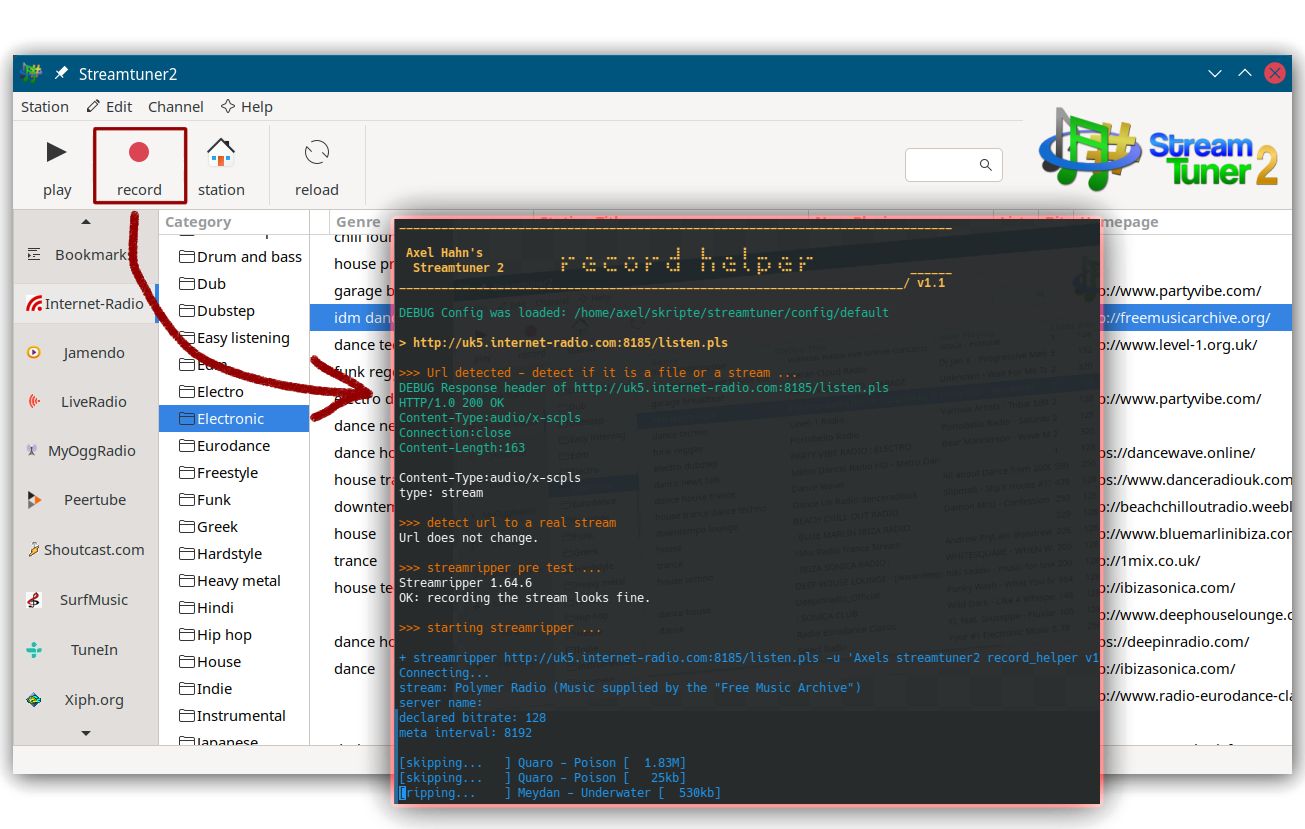
Aber das wurde schnell etwas mehr, weil ich mit den ersten Versionen des Wrapperskripts nun auch die verschiedenen Fehlerkonstellationen von Streamripper sehen konnte. Mit Hilfe von Curl wurden die Http Response Header angezeigt, was weitere Dinge aufzeigt. So ergaben sich diese Fehlermuster:
Problem: Fehler 404 oder 410.
Lösung: keine - der Stream existiert nicht mehr.
Problem: Fehler 50x
Lösung: Ein Streamingserver arbeitet derzeit nicht oder reagiert nicht schnell genug (Timeout). Lösen kann ich das nicht, aber eine Meldung ausgeben, damit man weiss, dass es wohl ein nur temporäres Problem gibt und man es später wieder versuchen kann.
Problem: die URL ist kein abspielbarer Stream, sondern eine Playlist.
Lösung: Die Playlist wird ausgelesen und die erste Streaming-URL daraus extrahiert. Anm.: Es gibt durchaus auch Playlisten-Typen, die Streamripper versteht.
Problem: Streamipper wird mit einem 403 abgewiesen.
Lösung: Manche Streamingserver verweigern den Zugriff je nach Useragent und unterbinden den Abruf durch den Streamripper. Aber im Kommandozeilenaufruf des Streamrippers kann man den Useragent umschalten.
Problem: Streamriupper meldet -28 [SR_ERROR_INVALID_METADATA]
Lösung: Keine - das ist ein Fehler im Streamripper selbst: er fordert Daten mit Http1.1 an, versteht aber selbst nur Http 1.0 und kommt dann mit der Antwort des Streamingservers nicht klar. Neben dem kurzen kryptischen Fehlercode wird dann ein ergänzender Hinweis eingeblendet. Es gibt einen nicht offiziellen Patch, mit dem man Streamripper neu complilieren kann - da die letzte Streamripperversion 2008 erschien, wird es wohl nicht mehr offiziell gefixt.
Weil es im Streamripper noch Plugins auf MODarchive und Jamendo gibt: ich habe noch Downloads mit Curl ergänzt:
- für Trackerfiles von MODarchive hinzugefügt (die Benamung der Zieldatei hole ich aus dem Http Response Header aus dem Attachment Filenamen)
- für jamendo MP3s (die Benamung der Zieldati erfolgt nach Aufruf von ffprobe - welches zu ffmpeg gehört - und wird aus Titel, Künstler und Jahr zusammengesetzt)
Im Dezember erschien die Version 1.1 - diese prüft die benötigten Tools und hat eine Erweiterung in der Cleanup-Funktionalität erfahren.
Die kleinen Heilungsfunktionen und verwertbare Meldungen für ein Debugging im Fehlerfalls sind doch immer hilfreich. Das scheint auch anderen zu gefallen. Mario Salzer verlinkte den Wrapper auf fossil.include-once.org - ich setze hiermit einen Link auch gern zu ihm zurück.
weiterführende Links:
Bash: starte für zig Server pro Tag etwas auf nur einzelnen Systemen
Ich habe da eine unbekannt lang laufende Aufgabe: ich möchte vom Backup-Tool Restic das Backup-Repository auf Version 2 migrieren. OK, eigentlich ist die Aufgabe ja egal. Alle 100+ Systeme kommen damit nicht in der Nacht durch.
Ich möchte …
- dass pro Nacht nur einige Systeme eine lang laufende Aufgabe wahrnehmen
- nach N Tagen soll sichergestellt sein, dass auch alle Systeme den Job 1x gemacht haben.
Mir kam der Modulus in den Sinn. [Weiterlesen…]