Mo, 14. Februar, 2022
Manchmal möchte man Hilfsausgaben in seinem Bash-Skript haben. 2 kleine Hildfsfunktionen definiert:
- _wd für write debug infos zur Ausgabe von optional sichtbaren Kommentaren und
- _we für write error zum Einblenden von Fehlermeldungen.
# write a debug message in yellow to STDERR
function _wd(){
test $DEBUG -eq 0 || echo -e ”e[33m# DEBUG: $*e[0m” >&2
}
# write error message in red to STDERR
function _we(){
echo -e ”e[31m# ERROR: $*e[0m” >&2
}
… und dann kann man in seinem Skript schreiben
# global var: enable debug output: 0|1
DEBUG=1
…
# example debug output
_wd ”show 3 oldest items in directory content”
ls -ltr | head -3
…
# example error
_we ”Something went wrong :-/”
exit 1
Mi, 28. Juli, 2021
Ich habe ein Shellskript. Dieses wird von mehreren Rechnern und auch von denen ggf. mehrfach aufgerufen.
Und nun möchte ich, dass viele dieser Aufrufe nicht parallel, sondern nacheinander ausgeführt werden - gern in der Reihenfolge des Aufrufs.
In diesem Fall war es ein Wrapper Skript [1], das mit Acme.sh [2] SSL Zertifikate via Let’s Encrypt [3] löst. Man kann ein Ansible [4] Skript parallelisieren: N Server möchten also gleichzeitig vielleicht dasselbe Zertifikat. Nur der erste Aufruf soll ein Zertifikat erstellen und die nachfolgenden Aufrufe, die “vielleicht” dasselbe Zertifikat bearbeitet haben wollen, sollen nicht ebenfalls das Zertifikat erstellen, sondern auf die Ausstellung des ersten Aufrufes warten und dann dessen erstellte Zertifikatsdateien verwenden.
Anm: Let’s Encrypt Live-Server blockieren nach zu vielen Aufrufen für dieselbe Domain für 1 Woche alle Zertifikats-Aktionen, was sehr unangenehm für ein produktives System “sein kann” - auch das möchte ich daher applikatorisch unterbinden.
Ein Queuing will ich nicht bauen oder Semaphoren nutzen. Alles zu kompliziert für diesen Zweck.
Mein Ansatz: die Prozessliste.
Ich baue zunächst eine Funktion - so rein für Wiederverwendungszwecke und/ oder für ein gesourctes Skript mit Funktionen. Aus der Prozessliste per ps -ef filtere ich alle Prozesse, die den Interpreter Bash enthalten und das Shellskript des eigenen Namens $0. Die Prozessliste wird nach der Spalte mit den PIDs numerisch sortiert. Das Filtern mit der Bash ist wichtig, dass nicht andere Prozesse mit demselben Shellskript - z.B. ein offener Editor, der das Skript gerade bearbeitet - versehentlich die echten Abrufe blockieren.
ps -ef | grep ”bash.*$0” | grep -v ”grep” | sort -k 2 -n
Wenn darin in der ersten Zeile …
[irgendein Kommando] | head -1
… die eigene Prozess ID $$ in der 2. Spalte steht, dann ist der gerade laufende Prozess derjenige mit der kleinsten PID und darf weiterlaufen.
Wenn nicht, gibt es ein sleep für ein paar Sekunden, bevor nochmals getestet wird.
Und so sieht die Funktion _wait_for_free_slot() dann aus:
showdebug=1
# ”neverending” loop that waits until the current process is
# the one with lowest PID
function _wait_for_free_slot(){
local _bWait=true
typeset -i local _iFirstPID=0
_wd ”— Need to wait until own process PID $$ is on top … ”
while [ $_bWait = true ];
do
_iFirstPID=$( ps -ef | grep ”bash.*$0” | grep -v ”grep” | sort -k 2 -n | head -1 | awk ’{ print $2}’ )
if [ $_iFirstPID -eq $$ ]; then
_bWait=false
_wd ”OK. Go!”
else
_wd ”- all instances”
test ${showdebug} && ps -ef | grep ”bash.*$0” | grep -v ”grep” | sort -k 2 -n
sleep 10
fi
done
}
# write debug output if showdebug is set to 1
function _wd(){
test ${showdebug} && echo ”DEBUG: $*”
}
Und dann baue ich in mein Skript jene Funktion _wait_for_free_slot ein - immer dort, wo ich eine sequentielle Ausführung wünsche. Wenn ich dasselbe Skript mit einem Parameter für die Hilfe-Ausgabe starte oder die Liste wartender Instanzen auflisten lasse, dann will ich eigentlich nicht auf die Abarbeitung aller vorherigen Instanzen warten. Naja, ihr seht vielleicht schon, worauf es hinausläuft. Bei jeder Aktion zum Erstellen, Erneuern oder Löschen eines Zertifikats wird die sequentielle Ausführung erzwungen, indem die Funktion _wait_for_free_slot in die erste Zeile geschrieben wird. Und bei den anderen Funktionalitäten lässt man den evtl. parallelisierten Aufruf zu.
#
# pulic function ADD certificate
#
function add(){
_wait_for_free_slot
// actions follow here …
}
weiterführende Links:
- IML certman Wrapper für Acme.sh mit DNS Authentication
- DOCs: os-docs.iml.unibe.ch/iml-certman/
- Acme.sh Let’ Encrypt Client als Bash Implementierung
- Let’s Encrypt Kostenlose SSL Zertifikate
- Ansible Automations Plattform
Mi, 14. Juli, 2021
Der grafische Software-Manager wollte pacman nicht aktualisieren … und wegen jenes Konflikts alle möglichen Pakete auch nicht.
Dann aktualisere ich halt “pamac upgrade pacman” von Hand und schaue, was passiert.
axel@mypc~> pamac upgrade pacman
(…)
vulkan-intel 21.1.4-1
(21.1.2-1) extra 2.3 MB
vulkan-radeon 21.1.4-1
(21.1.2-1) extra 1.7 MB
wireless-regdb 2021.04.21-1
(2020.11.20-1) core 10.3 kB
Wird installiert (10):
syndication 5.84.0-1
extra 1.0 MB
electron12 12.0.14-1
community 50.7 MB
layer-shell-qt 5.22.3-1
extra 23.1 kB
ksystemstats 5.22.3-1
extra 162.9 kB
pahole 1.21-1 extra
262.9 kB
nodejs-nopt 5.0.0-2
community 13.4 kB
libpamac 11.0.1-3 (Ersetzt:
pamac-common) extra 818.4 kB
kio-fuse 5.0.1-1 extra
70.3 kB
fakeroot 1.25.3-2 core
bison 3.7.6-1 core
Zu erstellen (2):
package-query 1.12-1 (1.10-1) AUR
zoom 5.7.1-1 (5.6.7-1) AUR
Wird entfernt (1):
pamac-common 10.0.6-2 (Konflikt mit: libpamac)
Download-Größe gesamt: 2.3 GB
Gesamtgröße installiert: 269.3 MB
Gesamtgröße entfernt: 9.5 MB
Build-Dateien bearbeiten : [e]
Transaktion durchführen ? [e/j/N] j
Warning: installing pacman (6.0.0-1) breaks dependency ’pacman<5.3′
required by package-query
Add package-query to remove
Fehler: Failed to prepare transaction:
could not satisfy dependencies:
- removing package-query breaks dependency ’package-query>=1.9′ required
by yaourt,
- if possible, remove yaourt and retry
Leider nein.
Beim Lesen von “installing pacman (6.0.0-1) breaks dependency ‘pacman<5.3' " dachte ich schon fast: oh, ein Henne-Ei-Problem?
Die Lösung:
Ich bin einfach dem letzten Rat in der Ausgabe gefolgt und habe yaourt entfernt.
axel@mypc~ [1]> pamac remove yaourt
Vorbereitung…
Abhängigkeiten werden überprüft…
Wird entfernt (1):
yaourt 1.9-2
Gesamtgröße entfernt: 849.9 kB
Transaktion durchführen ? [j/N] j
Removing yaourt (1.9-2)… [1/1]
Vorgang erfolgreich abgeschlossen.
Und nun nochmal der Versuch eines Updates …
axel@mypc~> pamac upgrade pacman
…
… hurra, nun klappt es!
weiterführende Links:
- manjaro.org (en)
Do, 8. Juli, 2021
Um die Frage des Titels zu beantworten, kommt man schnell auf ein … als root startet man
su - [USERNAME] -c [KOMMANDO]
Und wenn der User, unter dem ich das Kommando starten will, keine Shell hat? Tja, dann kommt eine Fehlermeldung der Art
This account is currently not available.
Wirklich sehr lange habe ich mir beholfen, dass ich dem User in der /etc/passwd eine Shell gegeben habe - das /usr/bin/nologin oder /bin/false wurde durch ein /bin/bash o.ä. ersetzt. Jaja, ganz generell fördern man [Kommando] oder [Kommando] –help hilfreiche Dinge zutage. Aber das ist völlig unnötig. Der “Trick” ist, dass man bei su mit dem Parameter -s eine Shell vorgibt, z.B. die /bin/sh.
su - [USERNAME] -c [KOMMANDO] -s /bin/bash
Um die Parameter wegzulassen und optisch zu vereinfachen, kann man auch eine kleine Funktion in sein Skript setzen:
# run a command as another posix user (even if it does not have a shell)
#
# example:
# runas www-data ”/some/where/mysript.sh”
#
# param string username
# param string command to execute. Needs to be quoted.
# param string optional: shell (default: /bin/sh)
function runas(){
local _user=$1
local _cmd=$2
local _shell=$3
test -z ”$_shell” && _shell=/bin/sh
su $_user -s $_shell -c ”$_cmd”
}
Dann kann man im Skript etwas kürzer schreiben:
runas [USERNAME] [KOMMANDO]
weiterführende Links:
- man7.org: Manpage für su
Do, 24. Juni, 2021
Wenn eine bestehende Mysql Replikation nicht mehr funktioniert, so half mir etliche Male im Laufe der Berufszeit als Webmaster beim Schweizer Radio DRS / Sysadmin Daseins an der Uni Bern ein top-down-Skript weiter. Wenn gerade Stress ist und man in der Situation nicht erst alle Kommandos zur Wiederinbetriebnahme des Slave nachschlagen mag, dann ist ist man froh, wenn man ein Skript dafür parat liegen hat.
reinit_mysql_replication.sh
Es gibt keine Parameter.
Installation:
Man benötigt einen Mysql Client. Ich hatte daher die Skripte am Mysql-Slave unterhalb /root zu liegen. Daher ist die Verbindung zum Slave ohne Passwort (wird aus der /root/.my.cnf gelesen).
Es wird auch vom eigenen Rechner aus funktionieren, der die Mysql-Ports von Master und Slave erreichen kann. Es ist nur “einen Tick” langsamer (sprich: bei vielen und/ oder grossen Datenbanken > 1 GB Gesamtgrösse nicht zu empfehlen).
Konfiguration:
Die *dist Datei ist umzukopieren und die Hostnamen und Root-Passwörter für Master + Slave sind zu setzen.
Start:
Das Skript reinit_mysql_replication.sh führt der Reihe nach folgende Aktionen aus: es …
- zeigt aktuellen Slave Status
- wartet dann auf ein RETURN, bevor die Replikation neu aufgesetzt wird
Aktionen zum Neuaufsetzen der Replikation: das Skript …
- liest die Position des Binlog am Master (per SQL “SHOW MASTER STATUS G;”)
- sperrt den Master für Schreibaktionen (”FLUSH TABLES WITH READ LOCK;”)
- holt aktuelle Datenbank-Dumps vom Master (mysqldump –all-databases –lock-all-tables …)
- hebt Schreibsperre am Master auf (”UNLOCK TABLES;”)
- stoppt den Slave (”STOP SLAVE G;”)
- importiert Dumps des Master auf dem Slave (cat $dumpMaster | mysql $paramdbSlave)
- setzt am Slave binfile und Position (”CHANGE MASTER TO MASTER_LOG_FILE = …” ; “CHANGE MASTER TO MASTER_LOG_POS = …”)
- startet den Slave (”START SLAVE G;”)
weiterführende Links:
- git-repo.iml.unibe.ch: iml-open-source/mysql-slave-scripts
Fr, 30. April, 2021
Ttyrec ist ein Open Source Werkzeug, mit dem man auf der Konsole alle Eingaben “mitschneiden” kann. Damit lassen sich Demos zur Handhabe von Installationen anfertigen oder ASCII Animationen aufzeichnen. Zur Wiedergabe gibt es ein ttyplay - oder für Webseiten auch einen Video Player, um eigene Online Dokumentationen zu ergänzen.
BTW: von ttyrec gibt es noch Portierungen in anderen Programmiersprachen, wie Python, Go, …
Aber zurück zu Manjaro. Es gibt mehrere AUR Pakete, um ttyrec auf Manjaro Linux builden zu lassen. Der Compilervorgang schlug bei mir aber jeweils fehl, weil ein man Verzeichnis bereits existiert:
Fehler: Vorgang konnte nicht abgeschlossen werden:
In Konflikt stehende Dateien:
- ovh-ttyrec-git: /usr/local/share/man existiert bereits im Dateisystem (gehört zu filesystem)
Die Lösung klingt etwas zu einfach … aber immerhin funktioniert es: man schaut einmal, was in diesem Verzeichnis ist und benennt es temporär um, um es dann anschliessend nach der Complilierung wiederherzustellen.
Gesagt - getan … und mit einem Underscore umbenannt:
axel@tux > sudo -i
root@tux# ls -l /usr/local/share/man
lrwxrwxrwx 1 root root 6 20. Jan 17:33 /usr/local/share/man -> ../man
root@tux# mv /usr/local/share/man /usr/local/share/man_
Ja, dann installieren / compilieren wir das nochmal … und starten pamac install ovh-ttyrec-git
root@tux# pamac install ovh-ttyrec-git
Warnung: ovh-ttyrec-git ist nur im AUR verfügbar
Vorbereitung…
Klone ovh-ttyrec-git Build-Dateien…
Running as unit: run-u161595.service
Finished with result: success
Main processes terminated with: code=exited/status=0
Service runtime: 309ms
Running as unit: run-u161597.service
Finished with result: success
Main processes terminated with: code=exited/status=0
Service runtime: 9ms
Überprüfe ovh-ttyrec-git Abhängigkeiten…
Abhängigkeiten werden aufgelöst…
Interne Konflikte werden überprüft…
Zu erstellen (1):
ovh-ttyrec-git v1.1.6.3.r0.gb8bdaab-1 AUR
Build-Dateien bearbeiten : [e]
Transaktion durchführen ? [e/j/N] j
Erstelle ovh-ttyrec-git…
Running as unit: run-u161604.service
Press ^] three times within 1s to disconnect TTY.
==> Making package: ovh-ttyrec-git v1.1.6.7.r1.ga13ca74-1 (Di 13 Apr 2021 17:24:30)
==> Checking runtime dependencies…
==> Checking buildtime dependencies…
==> Retrieving sources…
-> Updating ovh-ttyrec git repo…
Fetching origin
==> Validating source files with sha256sums…
ovh-ttyrec … Skipped
==> Removing existing $srcdir/ directory…
==> Extracting sources…
-> Creating working copy of ovh-ttyrec git repo…
Cloning into ’ovh-ttyrec’…
done.
Switched to a new branch ’makepkg’
==> Starting prepare()…
Looking for compiler… gcc
Checking if compiler can create executables… yes
Checking how to get pthread support… -pthread
Looking for libzstd… yes
Checking whether we can link zstd statically… no
Looking for isastream()… no
Looking for cfmakeraw()… yes
Looking for getpt()… yes
Looking for posix_openpt()… yes
Looking for grantpt()… yes
Looking for openpty()… yes (pty.h, libutil)
Checking for supported compiler options…
… OK -Wall
… OK -Wextra
… OK -pedantic
… OK -Wno-unused-result
… OK -Wbad-function-cast
… OK -Wmissing-declarations
… OK -Wmissing-prototypes
… OK -Wnested-externs
… OK -Wold-style-definition
… OK -Wstrict-prototypes
… OK -Wpointer-sign
… OK -Wmissing-parameter-type
… OK -Wold-style-declaration
… OK -Wl,–as-needed
… OK -Wno-unused-command-line-argument
You may run make now
==> Starting pkgver()…
==> Starting build()…
(…)
Vorgang erfolgreich abgeschlossen.
Das “erfolgreich abgeschlossen” klingt ja schonmal gut.
Jetzt muss ich nur noch das man Verzeichnis wiederherstellen. Durch das Complilieren entstand:
root@tux# ls -l /usr/local/share/man/man1/
insgesamt 12
-rw-r–r– 1 root root 641 13. Apr 17:24 ttyplay.1.gz
-rw-r–r– 1 root root 1751 13. Apr 17:24 ttyrec.1.gz
-rw-r–r– 1 root root 308 13. Apr 17:24 ttytime.1.gz
In /usr/local/share/ sieht es nun so aus:
root@tux# ls -l
insgesamt 4
lrwxrwxrwx 1 root root 6 20. Jan 17:33 man -> ../man
drwxr-xr-x 3 root root 4096 13. Apr 17:24 man_ttyrec
Hier muss man nur das man_ttyrec/man1 in das man hineinschieben.
root@tux# mv man_ttyrec/man1/ ../man
Und das war’s dann.
Hurra, das Paket ist erfolgreich installiert… und ttyrec lässt sich starten.
weiterführende Links:
- Wikipedia: ttyrec (en)
- Arch-Linux AUR: Suche nach ttyrec (en)
Mi, 28. April, 2021
Restic [1] ist ein in Go geschriebenes Backup-Tool für die Kommandozeile … oder zum Skripten. Es besteht aus einem einzigen Binary und hat keinerlei Abhängigkeiten zu Libs, Paketen oder irgendwas. Es erzeugt dedulizierte Backups: initial wird ein Vollbackup gemacht und dann nie wieder - es braucht dann nur noch inkrementelle Backups. Restic gibt es für Windows/ Mac/ Linux und diverse Plattformen (BSD, Solaris, Mips, … - siehe Releases (dort etwas scrollen :-) [2]).
Das hat was.
Daheim werfe ich gerade einen Http-Server als Backup-Endpoint auf die Synology [3].
Auf Systeme am Institut habe ich grob 150 Linux-Systeme - mit altem und neuen Linux Varianten verschiedener Distributionen. Ich habe ein Bash Skript geschrieben, das mit wget das Binary des Restic Client holt, entpackt und ins /usr/bin legt. Wer es für ein anderes OS oder Architektur braucht, müsste den Suffix “_linux_amd64” ersetzen … oder aber auch dynamisch machen (mit
uname -a
könnte man hinkommen).
#!/usr/bin/env bash
# ——————————————————
# CONFIG
# ——————————————————
resticversion=0.12.0
doLink=0
installdir=/usr/bin
resticfile=restic_${resticversion}_linux_amd64
downloadfile=${resticfile}.bz2
downloadurl=https://github.com/restic/restic/releases/download/v${resticversion}/${downloadfile}
# ——————————————————
# MAIN
# ——————————————————
echo
echo ”##### INSTALL RESTIC CLIENT into $installdir #####”
echo
echo —– DOWNLOAD
if [ ! -f ”${downloadfile}” ]; then
wget -O ”${downloadfile}.running” -S ”${downloadurl}”
&& mv ”${downloadfile}.running” ”${downloadfile}”
else
echo SKIP download
fi
echo
echo —– UNCOMPRESS
bzip2 -d ”${downloadfile}”
echo
echo —– INSTALL
mv ”${resticfile}” ”${installdir}”
chmod 755 ”${installdir}/${resticfile}”
rm -f ”${installdir}/restic” 2>/dev/null
test $doLink -eq 0 || ln -s ”${installdir}/${resticfile}” ”${installdir}/restic”
test $doLink -eq 0 && mv ”${installdir}/${resticfile}” ”${installdir}/restic”
echo
echo —– SELF-UPDATE
restic self-update
echo
echo —– RESULT:
test $doLink -eq 0 || ls -l ”${installdir}/${resticfile}”
ls -l ”${installdir}/restic”
echo
echo —– CURRENT VERSION:
restic version
echo
echo —– DONE
weiterführende Links:
- https://restic.net/ Homepage von Restic
- Github: Restic Releases
- Github: Skript zur Installation eines Restic Http Servers auf einer Synology
Mo, 7. Dezember, 2020
Mein Windows 10 war auf dem Stand 1804 und streikte beim Upgrade auf einen neueren Release. Ich habe irgendwann aufgegeben. Auf meinen Multiboot USB Stick kam das Windows 10 ISO und ich habe darüber ein “Update” gemacht. Das bisherige Windows, Programme und Benuterdaten landen in einem Ordner namens “Windows.old” - und man bekommt ein frisches Windows 10 drauf. Inkl. neuem Benutzer, ohne installierte Programme.
Man kann im “Windows.OLD” etwas spicken, welche Programme drauf waren und auch seine Benutzerdaten, Dokumente, whatever kopieren.
Als Backup nutze ich AOMEI Backup. Nach dessen Installation gab es keinerlei Backup-Sets. Falls auch wer mal sucht … man wird fündig unter im Windows.old\Users\All Users\AomeiBR\. Dieser Ordner ist zu kopieren nach
C:\Users\All Users\AomeiBR\
Beim nächsten Start von AOMEI Backup sind die alten Backup-Regeln wieder da.
weiterführende Links:
- Microsoft: Windows 10 ISO herunterladen
- Aomei Backup
Mi, 25. November, 2020
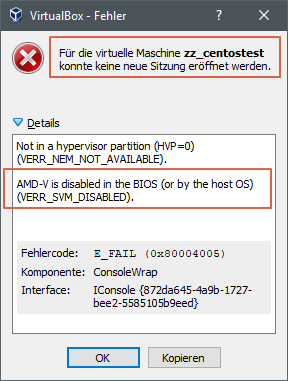
Ich habe auf meinem PC ein BIOS Update gemacht …
… woraufhin die Virtualbox VMs nicht mehr starteten:
AMD-V is disabled in the BIOS (or by the host OS) (VERR_SVM_DISABLED).
Fehlercode E_FAIL 0×80004005
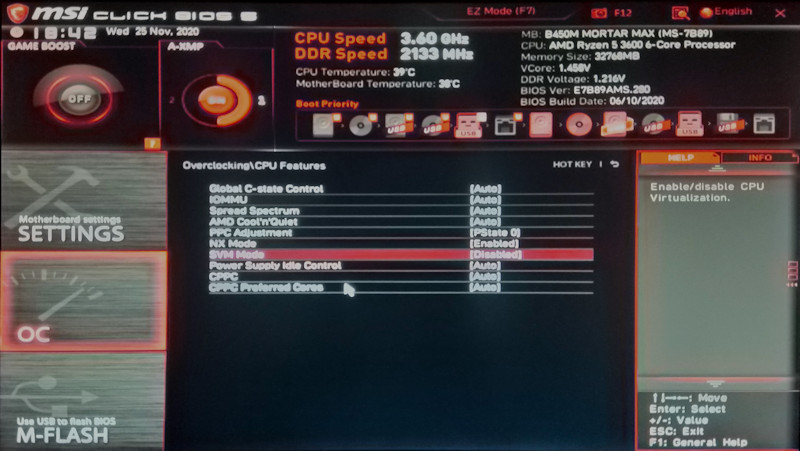
Lösung:
Im BIOS muss nach dessen Update die CPU Virtualisierung aktiviert werden. In “meinem” BIOS nennt sich das Feature Overclocking -> CPU Features -> SVM Mode … jene Einstellung stand auf “Disabled” und musste aktiviert werden.
Beim Verlassen des BIOS die Änderungen speichern und nach dem nächsten Start des Betriebssystems starten die virtuellen Maschinen wieder.
Fr, 30. Oktober, 2020
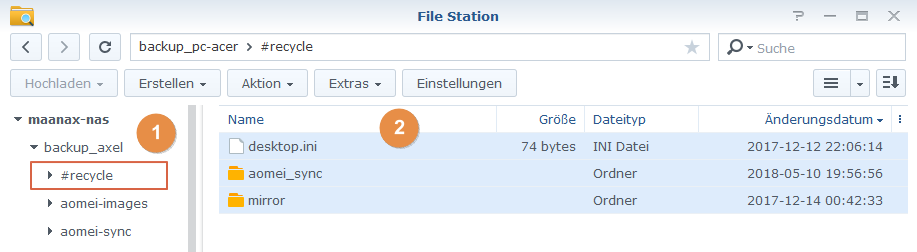
Auf meiner Synology war immer weniger freier Platz. Kann ja passieren, aber auch deshalb, wenn man den Papierkorb bei Verzeichnisfreigaben (Shares) aktiviert hat.
Klingt banal, aber ist bei wenig verbliebenem Platz mal sicher einen Blick wert. Also, bevor man sich neue Disks kauft.
- In der Web GUI die Filestation öffnen
- in einem Ordner schauen, ob es ein #recycle Verzeichnis gibt
- Wenn ja: alle Einträge markieren … rechte Maustaste und löschen … und vielleicht über etwas mehr freien Platz freuen.