Topgrade mit Notifikationen unter Linux
Ich hatte mir jüngst Topgrade [1] installiert. Dies ist ein universeller System-Updater für Windows, Mac und etliche Linux Distributionen.
Ich war sofort happy - und so wurde es kurzerhand auf meinem Linux PC in einen Cronjob eingebunden.
Damit ich nicht im Blindflug bin, wollte ich per Desktop-Notifikation benachrichtigt werden. Folglich musste zusätzlich ein kleines Bash-Skript für einen Wrapper [2] her. Jener startet ganz einfach notfify-send vor und nach Ausführung von topgrade. Bei Beendigung mit Fehler bleibt der Hinweis bis Klick stehen. So verpasse ich auch bei Conjobs im Hintergrund keine fehlgeschlagenen Updates.
Das ist zu einfach :-)
Naja, fast. Der tricky Part ist: die Variable DBUS_SESSION_BUS_ADDRESS ist richtig zu belegen, dass eine Nachricht von einem eigentlich “leisen Hintergrund-Job” den Weg zum Desktop eines am Bildschirm sitzenden Benutzers findet. Shellskript-Bastler können sich das im Quellcode ansehen - für alle anderen funktioniert es halt out-of-the-box.
Weiterführende Links:
IML Artikel: IT-Monitoring mit “Freier Software” ist online
Es hat 1.5 Jahre gebraucht vom ersten Entwurf bis zur Veröffentlichung. Scheinbar ist es komplizierter, als gedacht. Aber nun ist es vollbracht: der Artikel ist online.

Ich bin seit 12 Jahren am IML angestellt und erstmals sind Worte wie “Open source” oder “Freie Software” in einem Artikel unserer Instituts-Webseite aufgetaucht. Und das, obwohl seit über 10 Jahren in der Server-IT ausschliesslich Linux und Freie Software zum Einsatz kommt.
Was braucht es, um im Blick zu halten, ob die Infrastruktur rund läuft? Wir verwenden mehrere Monitoring-Werkzeuge für
- Logging
- Cronjobs
- System-Monitoring und
- Applikations-Monitoring
Das System-Monitoring Icinga2 ist unser zentraler Sammelpunkt, bei der Störungsinformationen zusammenfliessen - so hat man alles im Blick, ohne zwischen verschiedenen Fenstern (Tabs) hin- und herspringen zu müssen.
Wir setzen auf Freie Software und stellen im Umkehrzug Eigenentwicklungen als Freie Software zur Verfügung.
Am konkreten Beispiel unseres IT Monitorings wird das gelebte Prinzip von Nehmen und Geben beleuchtet.
Docker Fehler - Archives directory /var/cache/apt/archives/partial is missing. - Acquire (2: No such file or directory)
Die Aufrufe zum frischen Erstellen eines Containers für meine lokale Webentwicklung per
docker-compose -p <NAME> --verbose up -d --remove-orphans --build
lieferte nunmehr beim Debian-Image für Apache
=> ERROR [appmonitor-web stage-0 2/5] RUN apt-get update && apt-get install -y git unzip zip 2.1s ------ > [appmonitor-web stage-0 2/5] RUN apt-get update && apt-get install -y git unzip zip: 0.275 Get:1 http://deb.debian.org/debian bookworm InRelease [151 kB] 0.302 Get:2 http://deb.debian.org/debian bookworm-updates InRelease [55.4 kB] 0.310 Get:3 http://deb.debian.org/debian-security bookworm-security InRelease [48.0 kB] 0.392 Get:4 http://deb.debian.org/debian bookworm/main amd64 Packages [8788 kB] 0.631 Get:5 http://deb.debian.org/debian bookworm-updates/main amd64 Packages.diff/Index [10.6 kB] 0.642 Get:6 http://deb.debian.org/debian-security bookworm-security/main amd64 Packages [169 kB] 0.692 Get:7 http://deb.debian.org/debian bookworm-updates/main amd64 Packages T-2024-04-23-2036.10-F-2023-12-15-1408.04.pdiff [8693 B] 0.700 Get:7 http://deb.debian.org/debian bookworm-updates/main amd64 Packages T-2024-04-23-2036.10-F-2023-12-15-1408.04.pdiff [8693 B] 1.153 Fetched 9230 kB in 1s (10.1 MB/s) 1.153 Reading package lists... 1.445 Reading package lists... 1.754 Building dependency tree... 1.845 Reading state information... 1.950 git is already the newest version (1:2.39.2-1.1). 1.950 unzip is already the newest version (6.0-28). 1.950 zip is already the newest version (3.0-13). 1.950 E: Archives directory /var/cache/apt/archives/partial is missing. - Acquire (2: No such file or directory)
Mit der Meldung
Archives directory /var/cache/apt/archives/partial is missing. - Acquire (2: No such file or directory)
… findet man im Web zum Ziel.
In meinem Debian-basierten Dockerfile gab es zum Installieren diese Anweisungen:
# install packages
RUN apt-get update && apt-get install -y {{APP_APT_PACKAGES}}
Dies wurde ersetzt per
# install packages
RUN rm -rf /var/lib/apt/lists/*
RUN mkdir -p /var/cache/apt/archives/partial
RUN apt-get update
RUN apt-get install -y {{APP_APT_PACKAGES}}
Man löscht vor dem apt-get erst ein Verzeichnis … und legt ein anderes an.
Wie magisch: und schon funktioniert der Build wieder.
Weiterführende Links
Härten unseres Restic-Backups
Unser Server Backup mit dem IML Backup [1] am Institut mit 150+ Systemen lief über Jahre mit Restic [2] und via SFTP zu einem Storage. Mit Restic bin ich soweit sehr zufrieden: es verschlüsselt Daten lokal vor der Übertragung und muss nach einem Initialbackup nur noch inkrementelle Backups machen. Auch das Restore von einzelnen Dateien und Ordnern hat uns nie im Stich gelassen. Insbesondere das Mounten mit Fuse ist ein hilfreiches Feature.
Dann sah ich im Januar 2024 das Videos des CCC [3]. Auf der “wichtigsten Folie des ganze Vortrags” waren Anforderungen an Backups gelistet, um sich gut gegen Ransomware-Verschlüsselungen der Infrastruktur zu wappnen. Bei vielen Punkten waren wir demnach bereits gut gewappnet. Aber es gab unschöne Schwachpunkte. Da diese jeweils eine Rechteausweitung als root voraussetzen, war dies mit “kalkulierten Risiko”.
Ein System kann seine eigenen Backup-Daten löschen.
Damit Backups nicht übermässig gross werden, werden alle N Tage im Anschluss des backups alte Daten älter 180 Tage gelöscht. Wenn ein Sysem gekapert plus der root-Account erreicht würde, kann durch böswilliges Setzen eines Delta statt 180 Tage auf 0 Tage setzend ist so ziemlich alles weggeputzt werden.
Ein System kann theoretisch Backups anderer Systeme löschen.
Bei Einbruch und Rechteausweitung auf root könnte wäre Folgendes denkbar: alle Systeme schreiben auf das Backup-Ziel mit demselben SSH-User. Auf der Zielseite gehören die Dateien demselben User und thoretisch könnte ein System Zugriff auf Backup-Daten eines anderen Systems erhalten und diese zwar nicht entschlüsseln, aber wg. Schreibrechten eben auch löschen.
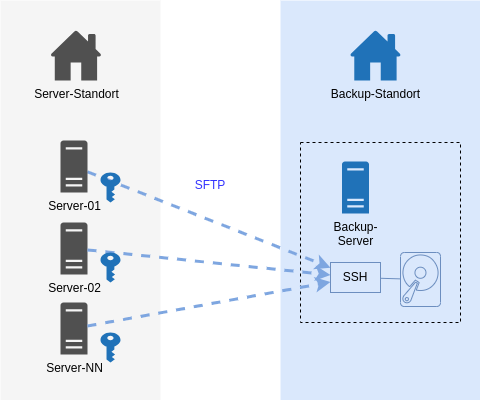
Es geht nun auch besser.
Auf dem Backup-Endpoint wurde nun der Restic-Rest-Server [4] installiert, der als Systemd Service eingerichtet wurde. Die Backup-Clients kommunizieren nun statt via SSH mit HTTPS. Sie teilen nicht mehr den auf allen Systemen gleichen privaten SSH-Schlüssel.
In den Startparametern des Rest-Servers wurden diese Optionen aufgenommen, um folgende Härtungen zu erreichen:
Ein User (Server) darf nur sein eigenes Repository beschreiben.
Option:
--private-repos
Das Unterbindet das Ausbrechen auf Backup-Daten anderer Systeme.
Jeder Backup-Client (unsere Server) bekommt einen eigenen User und ein eigenes Http-Auth Passwort zugewiesen.
Auf dem Restic Rest Server werden Usernamen und das verschlüsselte Passwort in eine .htpasswd eingetragen.
Stolperfalle: Es böte sich an, die Benutzer gleich zu benennen, wie den Server. Eine Limitierung in der der .htpasswd lässt einen Punkt im Benutzernamen jedoch nicht zu. Aber das Ersetzen des Punkts im FQDN durch einen Unterstrich führt zu keinerlei Überschneidungen. Dem schliest sich an, dass das Backup-Verzeichnis nun statt [Backup-Dir]/
Ein User (Server) darf Daten nur anhängen.
Option:
--append-only
Kurz: Löschen ist nicht mehr möglich. Das klingt sicher.
Der Pferdefuss: unser auf jedem Einzelsystem befindliche Restic Prune Job zum Löschen älter N Tage funktioniert so nicht mehr. Ich habe es auch probiert: es wird mit einem 40x Statuscode zurückgewiesen.
Unsere Abhilfe sieht wie folgt aus: auf dem Backup-Zielserver läuft nun ein Cronjob, der über alle Backup-Repos das Pruning macht [4]. Wir lassen es erkennen, wie alt das letzte Prubg war und pausieren das Prune auf ein Repository dann für N Tage. Damit Restic auf Inhalte zugreifen kann, muss das Passwort zum Entschlüsseln aller Serverdaten für das Skript greifbar sein. Wir generieren mit Ansible eine Konfigurationsdatei, die alle Benutzernamen und Restic-Verschlüsselungspasswörter am Backup-System niederschreibt. Diese Datei gehört root:root und hat die Rechte 0400.
Zustand NEU:
Das Ergebnis ist derselbe Datenfluss - nur mit einem anderen Protokoll - Https statt ssh. Entscheidend sind die 2 o.g. Optionen für den Restic Server auf dem Backup-Ziel.
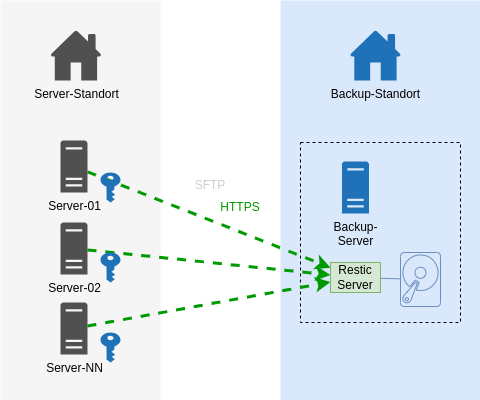
Dies war eine Beschreibung mit hoher Flughöhe mit weniger technischen Details. Bei Fragen nutzt gern die Kommentarfunktion oder fragt mich an.
Weiterführende Links:
Daux auf Manjaro installieren
In Manjaro Linux gibt es Pakete - darunter auch PHP und ist schnell installiert. Den Composer nachzuschieben ist ein Nobrainer und dann kann man
composer global require daux/daux.io
aufrufen, um Daux lokal zu installieren. Das klingt alles straight forward. Wie bei allen anderen Distros mit Paketmanagement auch.
Es gibt jedoch unter Manjaro ein ABER: ein “daux generate” verweigert seinen Dienst, sobald man das Generieren einer Offline-Javascript Suche in einem Doc Projekt aktiviert hat. Es fehle die Funktion iconv. Das entsprechende PHP-Paket kann man installieren, aber dann wird der Apache httpd gleichsam installiert.
Daher nochmal Reset und von vorn. Wie bekommt man Daux nun inkl. Suche zum Laufen? Also, ohne einen Webserver installieren zu müssen und rein mit PHP-CLI?
(1) PHP-Quelle einbinden
Es gibt neben Manjao-Paketen weitere Quellen, die man einbinden kann.
https://aur.archlinux.org/pkgbase/php82
Man folge der dortigen Anleitung:
(a) als root in der /etc/pacman.conf eintragen
[home_el_archphp_Arch] Server = https://download.opensuse.org/repositories/home:/el:/archphp/Arch/$arch
(b) als root in der Shell:
key=$(curl -fsSL https://download.opensuse.org/repositories/home:el:archphp/Arch/$(uname -m)/home_el_archphp_Arch.key)
fingerprint=$(gpg --quiet --with-colons --import-options show-only --import --fingerprint <<< "${key}" | awk -F: '$1 == "fpr" { print $10 }')
pacman-key --init
pacman-key --add - <<< "${key}"
pacman-key --lsign-key "${fingerprint}"
Und zum Aktualisieren der Paket-Datenbank
pacman -Syy
(2) PHP Pakete installieren
Man installiere diese Pakete:
php82 php82-cli php82-iconv php82-mbstring php82-openssl php82-phar
Jene werden benötigt, um den Composer zu compilieren.
(3) php verfübar machen
Noch schnell ein Zwischenschritt.
Nach Installieren von PHP82-cli wird bei Eingabe “php” auf der Shell kein Binary gefunden. Das, weil es “php82” heisst - Daux wird aber nach “php” suchen. “which php82” verrät uns, dass es unter /usr/bin liegt (oder aber man schaut in die Paket-Details).
Wie lösen wir das? Ich würde zu einem Softlink greifen.
Man kann sich mit “echo $PATH” ansehen, welche bin-Verzeichnisse verfügbar sind. Weil ich bei mir am Rechner nur allein mit meinem lokalen User arbeite, lege ich den Softlink unter meinem $HOME an. Soll es global für alle User funktionieren, würde ich den Softlink in /usr/bin/ anlegen.
cd ~/bin/ ln -s /usr/bin/php82 php
Test: Wenn anschliessend “php -v” nun etwas ausgibt, dann passt es.
(4) PHP Composer 8.2 installieren
Nun kann man den php82-composer aus den AUR installieren. AUR muss man folglich im Paketmanager aktiviert haben.
(5) Daux installieren
composer82 global require daux/daux.io
Also … statt “composer” ist “composer82” entsprechend der PHP-Version aufzurufen.
(6) Daux verwenden
daux generate
… voila: funktioniert nun inkl. Suche! Viel Spass!
Weiterführende Links:
- daux.io (en)
- Arch :: Package Base Details: php82 (en)
Dokus für 2 Bash-Projekte
Ich skripte meine Dinge hauptsächlich in Bash.
Und weil niemand etwas nutzt, was nicht dokumentiert ist, habe ich 2 neue Dokumentationen online gestellt:
(1)
Kürzlich habe ich eine Bash-Komponente geschrieben, die die Handhabe der ANSI Farben vereinfacht.
Man kann eingfach Farben für Vordergrund und Hintergrund setzen - mit Namen einer Farbe oder HTML-CSS-Farbangabe.
Doc zu bash_colorfunctions
Rein zur Veranschaulichung: damit kann man farbige Texte ausgeben mit
color.echo "white" "green" "Yep, it seems to work!"
… oder aber die Farbe nur setzen, um nachfolgende Kommandos in jener Farbe die Ausgabe machen zu lassen. Zum Aufheben der Farbdefinition ruft man ein color.reset auf:
color.fg "blue" ls -l color.reset
(2)
Schon einige Monate auf Github ist mein Projekt, das mit Hilfe eines lokal installiertten Nginx den Zugriff auf eine Webapplikation als Docker Container mit Https und mit Namen der Applikation ansprechen lässt.
Doc zu nginx-docker-proxy
Beide Projekte sind freie Software und Opensource.
Bash: lsup zur Anzeige der Dateiberechtigungen
Wie oft ich das schon im Linux Filesystem gebraucht habe: in einem aktuellen oder angegebenen Verzeichnis prüfen, ob der Linux-Benutzer XY bis dorthin “durchkommt” und Berechtigungen in einem Verzeichnis oder auf eine Datei hat.
Also schrieb ich ein Shellskript. Man ruft es mit einem Parameter für ein zu prüfendes Verzeichnisses auf. Oder ohne Parameter für das aktuelle Verzeichnis.
Ich fange mal mit dessen Ausgabe an:
$ lsup drwxr-xr-x 1 root root 244 Apr 2 23:34 / drwxr-xr-x 1 root root 100 Jun 4 2022 /home drwx------ 1 axel autologin 1.7K May 25 18:17 /home/axel drwxr-xr-x 1 axel autologin 232 May 25 19:50 /home/axel/tmp
Ab dem Root-Verzeichnis werden mit ls -ld alle Verzeichnisebenen bis zum angegebenen Punkt angezeigt.
Syntax:
$ lsup -h ===== LSUP v1.3 :: make an ls upwards ... ===== Show directory permissions above by walking from / to the given file. You can add no or one or multiple files as params. SYNTAX: lsup Walk up from current directory lsup FILE [FILE N] Walk up from given file/ directory If the target is relative it will walk up to the current directory lsup -h Show this help and exit EXAMPLES: lsup lsup . lsup /var/log/ lsup my/relative/file.txt lsup /home /tmp /var
Zur Installation: als User root;: cd /usr/bin/ und nachfolgenden Code in eine Datei namens “lsup” werfen und ein chmod 0755 lsup hinterher.
#!/usr/bin/env bash
# ======================================================================
#
# Make an ls -d from root (/) to given dir to see directory
# permissions above
#
# ----------------------------------------------------------------------
# 2020-12-01 v1.0 Axel Hahn
# 2023-02-06 v1.1 Axel Hahn handle dirs with spaces
# 2023-02-10 v1.2 Axel Hahn handle unlimited spaces
# 2023-03-25 v1.3 Axel Hahn fix relative files; support multiple files
# ======================================================================
_version=1.3
# ----------------------------------------------------------------------
# FUNCTIONS
# ----------------------------------------------------------------------
function help(){
local self=$( basename $0 )
cat <<EOH
===== LSUP v$_version :: make an ls upwards ... =====
Show directory permissions above by walking from / to the given file.
You can add no or one or multiple files as params.
SYNTAX:
$self Walk up from current directory
$self FILE [FILE N] Walk up from given file/ directory
If the target is relative it will walk up
to the current directory
$self -h Show this help and exit
EXAMPLES:
$self
$self .
$self /var/log/
$self my/relative/file.txt
$self /home /tmp /var
EOH
}
# ----------------------------------------------------------------------
# MAIN
# ----------------------------------------------------------------------
if [ "$1" = "-h" ]; then
help
exit 0
fi
test -z "$1" && "$0" "$( pwd )"
# loop over all given params
while [ $# -gt 0 ]; do
# param 1 with trailing slash
mydir="${1%/}"
if ! echo "$mydir" | grep "^/" >/dev/null; then
mydir="$( pwd )/$mydir"
fi
ls -ld "$mydir" >/dev/null 2>&1 || echo "ERROR: File or directory does not exist: $mydir"
ls -ld "$mydir" >/dev/null 2>/dev/null || exit 1
mypath=
arraylist=()
arraylist+=('/')
IFS="/" read -ra aFields <<< "$mydir"
typeset -i iDepth=${#aFields[@]}-1
for iCounter in $( seq 1 ${iDepth})
do
mypath+="/${aFields[$iCounter]}"
arraylist+=( "${mypath}" )
done
# echo ">>>>> $mypath"
eval "ls -lhd ${arraylist[*]}"
shift 1
test $# -gt 0 && echo
done
# ----------------------------------------------------------------------
Viel Spass damit!
Timeshift und Prozentrechnung
Timeshift speichert Snapshots eines Linux-Systems. Es kann sich u.a. als Hook in den Paketmanager einklinken und vor jedem Update einen Snapshot anlegen, um im Falle eines Nicht-Funktionierens zurückzurollen.
- Wenn die Snapshots auch auf der Systemdisk abgelegt werden, wird das Grub-Menü um die Auswahl der letzten Snapshots erweitert.
- Falls nicht, wird ein Rsync zum Sichern des Snapshots bemüht. Wenn man sein Linux booten kann (also notfalls von USB Stick), kann man Timeshift auch so einen anderen Stand wiederherstellen lassen.
Einen kleinen Schönheitsfehler gibt es aber. Im CLI Modus gibt Timeshift eine Fortschrittsinfo aus. Dumm nur, wenn es bei 100% gar nicht fertig ist.
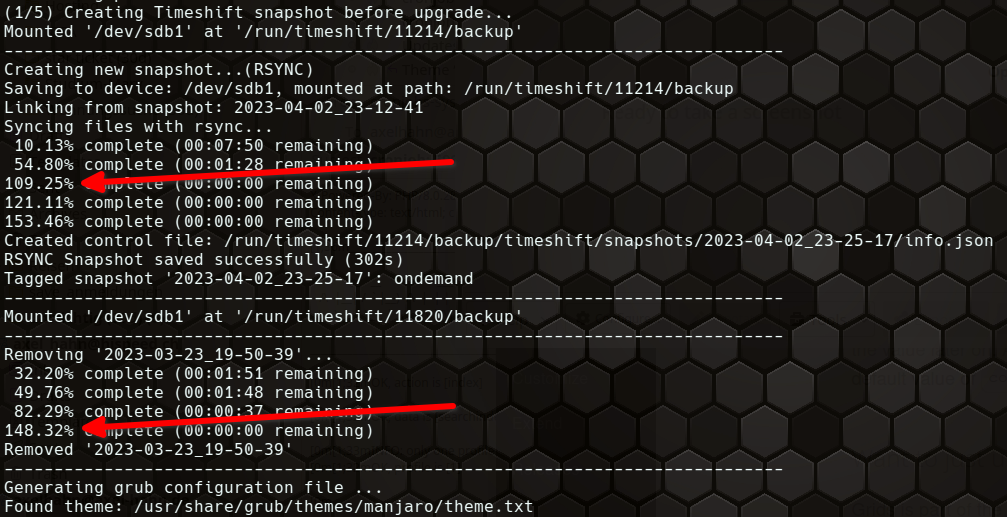
Naja, ich kann darüber hinwegsehen. Wenn der Moment kommt, wo man mal ein Backup braucht, ist man froh um jeden verfügbaren Zwischenstand von so vielen Informationen wie möglich.
Ich fahre auf meinen Linux-PCs mit einer Kombination von Timeshift und Restic (IML Backup). Aber man will ja selbst keinen interaktiven Aufwand und sich nicht darum kümmern. Aber ich weiss, dass ich mich auf das Funktionieren beider Varianten in deren Kombination mit Snapshots und Datei-Backups verlassen kann.
Weiterführende Links
Fehlermuster im Streamripper
Ich schrieb vor nicht allzu langer Zeit einen Blogeintrag, um in Streamripper2 die Aufnahme-Funktion besser zu nutzen.
Diese muss man konfigurieren - also schlusendlich einen Kommandozeilenaufruf hinterlegen. Klassischerweise wird für Radiostreams das Tool Streamripper konfiguriert - und um eine optische Ausgabe zu haben, setzte man einen Konsolenaufruf davor. Ich fand das sehr bescheiden - sehr oft war bei egenen Versuchen war das Konsolenfenster gleich wieder zu und damit auch eine etwaige Fehlermeldung weg. Das ist doch nur unbefriedigend.
So fing alles an. Ich kann zum Glück etwas Shellprogrammierung.
Es sollte zunächst ein kleiner Wrapper sein, der anzeigt, welches Kommando mit welchen Parametern aufgerufen wird - und im Falle eines Abbruchs mich auch den Fehlertext lesen lässt.
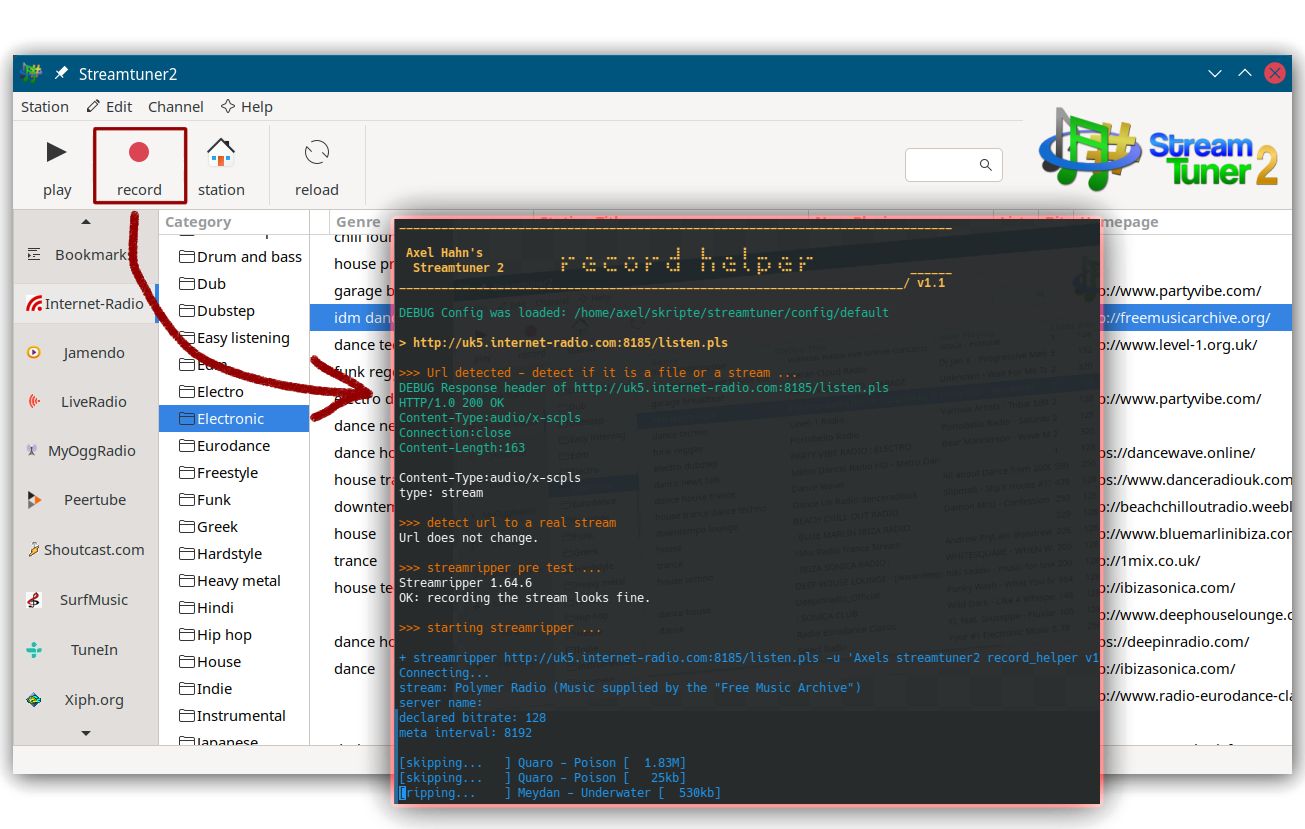
Aber das wurde schnell etwas mehr, weil ich mit den ersten Versionen des Wrapperskripts nun auch die verschiedenen Fehlerkonstellationen von Streamripper sehen konnte. Mit Hilfe von Curl wurden die Http Response Header angezeigt, was weitere Dinge aufzeigt. So ergaben sich diese Fehlermuster:
Problem: Fehler 404 oder 410.
Lösung: keine - der Stream existiert nicht mehr.
Problem: Fehler 50x
Lösung: Ein Streamingserver arbeitet derzeit nicht oder reagiert nicht schnell genug (Timeout). Lösen kann ich das nicht, aber eine Meldung ausgeben, damit man weiss, dass es wohl ein nur temporäres Problem gibt und man es später wieder versuchen kann.
Problem: die URL ist kein abspielbarer Stream, sondern eine Playlist.
Lösung: Die Playlist wird ausgelesen und die erste Streaming-URL daraus extrahiert. Anm.: Es gibt durchaus auch Playlisten-Typen, die Streamripper versteht.
Problem: Streamipper wird mit einem 403 abgewiesen.
Lösung: Manche Streamingserver verweigern den Zugriff je nach Useragent und unterbinden den Abruf durch den Streamripper. Aber im Kommandozeilenaufruf des Streamrippers kann man den Useragent umschalten.
Problem: Streamriupper meldet -28 [SR_ERROR_INVALID_METADATA]
Lösung: Keine - das ist ein Fehler im Streamripper selbst: er fordert Daten mit Http1.1 an, versteht aber selbst nur Http 1.0 und kommt dann mit der Antwort des Streamingservers nicht klar. Neben dem kurzen kryptischen Fehlercode wird dann ein ergänzender Hinweis eingeblendet. Es gibt einen nicht offiziellen Patch, mit dem man Streamripper neu complilieren kann - da die letzte Streamripperversion 2008 erschien, wird es wohl nicht mehr offiziell gefixt.
Weil es im Streamripper noch Plugins auf MODarchive und Jamendo gibt: ich habe noch Downloads mit Curl ergänzt:
- für Trackerfiles von MODarchive hinzugefügt (die Benamung der Zieldatei hole ich aus dem Http Response Header aus dem Attachment Filenamen)
- für jamendo MP3s (die Benamung der Zieldati erfolgt nach Aufruf von ffprobe - welches zu ffmpeg gehört - und wird aus Titel, Künstler und Jahr zusammengesetzt)
Im Dezember erschien die Version 1.1 - diese prüft die benötigten Tools und hat eine Erweiterung in der Cleanup-Funktionalität erfahren.
Die kleinen Heilungsfunktionen und verwertbare Meldungen für ein Debugging im Fehlerfalls sind doch immer hilfreich. Das scheint auch anderen zu gefallen. Mario Salzer verlinkte den Wrapper auf fossil.include-once.org - ich setze hiermit einen Link auch gern zu ihm zurück.
weiterführende Links:
Bash: starte für zig Server pro Tag etwas auf nur einzelnen Systemen
Ich habe da eine unbekannt lang laufende Aufgabe: ich möchte vom Backup-Tool Restic das Backup-Repository auf Version 2 migrieren. OK, eigentlich ist die Aufgabe ja egal. Alle 100+ Systeme kommen damit nicht in der Nacht durch.
Ich möchte …
- dass pro Nacht nur einige Systeme eine lang laufende Aufgabe wahrnehmen
- nach N Tagen soll sichergestellt sein, dass auch alle Systeme den Job 1x gemacht haben.
Mir kam der Modulus in den Sinn. [Weiterlesen…]